Suhardi, Mengel, Fellbaum: Kontext-unabhängige Lauterkennung von Telefonsprache
Kontext-unabhängige Lauterkennung von Telefonsprache unter Verwendung von Hidden-Markov-Modellen
Suhardi
Institut für Nachrichtentechnik und theoretische Elektrotechnik
TU Berlin
suhardi@ftsu00.ee.tu-berlin.de
Andreas Mengel
Institut für Kommunikationswissenschaft
TU Berlin
mengel@kgw.tu-berlin.de
Klaus Fellbaum
Lehrstuhl Kommunikationstechnik
BTU Cottbus
fellbaum@kt.tu-cottbus.de
Kurzfassung
Es wird die kontext-unabhängige Lauterkennung
von Telefonsprache unter Verwendung von
Hidden-Markov-Modellen beschrieben. Jeder
Laut wird durch ein kontinuierliches
5-Zustands-Links-Rechts-HMM
modelliert. Das HMM
wird mit der Phondat-Sprachdatenbank trainiert,
deren Abtastfrequenz auf 8 kHz herabgesetzt und
deren Bandbreite auf 300-3400 Hz begrenzt wurde.
Zur Rauschbefreiung wird bei der Vorverarbeitung
eine Lin-Log-RASTA-Filterung
eingesetzt.
Zum Testen dient ein Teil der
TUBTEL-Sprachdatenbank.
Schlüsselwörter: Lauterkennung, Telefonsprache,
Hidden Markov Modelle.
1. Einführung
Das Ziel dieser Arbeit besteht darin,
durch eine experimentelle Untersuchung
herauszufinden, wie man
ein kontext-unabhängiges Lauterkennungssystem
für Telefonsprache
mit einer Studio-Qualitäts-Sprachdatenbank
trainieren kann. Hierzu werden
eine Studio-Qualitäts-Sprachdatenbank
(Phondat I und II [1]) und
eine Telefon-Qualitäts-Sprachdatenbank
(TUBTEL [2]) für die
deutsche Sprache verwendet. Die Phondat-Sprachdatenbank
ist auf Lautebene, die TUBTEL-Sprachdatenbank
teilweise auf Wort-Ebene gelabelt. Die Motivation für
unsere Arbeit liegt darin, daß die Erstellung und
Segmentierung von Sprachaufnahmen zeit- und
kostenintensiv ist, so daß die Wiederwendung von
verfügbarem Sprachmaterial naheliegt - auch wenn
dieses Material in seinen technischen Daten vom eigenen
Material abweicht.
Eine ähnliche Vorgehensweise ist
bereits für die englische Sprache erfolgreich
erprobt worden [3, 4].
Der Unterschied zwischen der Studio-Qualitäts-Sprache
und der Telefon-Qualitäts-Sprache liegt in deren
akustischen Eigenschaften. Die Phondat-Sprachdatenbank
hat 16 kHz Abtastfrequenz, 8 kHz Bandbreite, und sie
ist rauschfrei. Die TUBTEL-Sprachdatenbank hat eine
Abtastfrequenz von 8 kHz, 300-3400 Hz Bandbreite und ist
rauschbehaftet. Die Rauschanteile bei der Telefonsprache
ergeben sich aus gefaltetem und
additivem Rauschen sowie den nichtlinearen Eigenschaften
des Amplituden- und Phasengangs des Telefonkanals.
Sie sind die
Ursache für die Verminderung der Erkennungsrate.
Die Bandbreite spielt für die Verminderung der
Erkennungsrate bei der Telefonsprache nur
eine geringe Rolle [5].
Zwecks Anpassung der akustischen Eigenschaften werden
eine Decimation zur Verminderung der Abtastfrequenz
der Phondat-Sprachdatenbank und eine Bandpaß-Filterung zur
Bandbreitenbegrenzung (300-3400 Hz) durchgeführt.
Eine Lin-Log-RASTA-Filterung reduziert die Rauschanteile
der TUBTEL-Sprachdatenbank [4].
2. Automatische Segmentierung.
Die automatische Segmentierung dient einerseits
zur Untersuchung der Eignung einer
Lin-Log-RASTA-PLP-Analyse
für die Segmentierung der Laute bei gefaltetem und
additivem Rauschen und andererseits
zur Vorbereitung des Testmaterials für die
kontext-unabhängige Lauterkennung von Telefonsprache.
Diese Segmentierung basiert auf dem HMM-Verfahren.
Für jeden Laut wird ein kontinuierliches HMM trainiert.
Für die Labelung der Trainingsdaten wurden 52 Laute nach
SAMPA-Konvention unterschieden.
Entspechend der Transkription der zu segmentierenden
Sprachdatei werden die HMMs der Lautmodelle verkettet.
Durch den Viterbi-Algorithmus werden der optimale Anfangs- und
Endpunkt eines jeden Lautes ermittelt [7].
Merkmalsextraktion
Hierbei werden die Cepstral-Koeffizienten als Merkmale eingesetzt.
Die Berechnung der Cepstral-Koeffizienten wird mittels der
Lin-Log-RASTA-PLP-Analyse durchgeführt, da diese
für die Spracherkennung von
Telefonsprache gut geeignet ist [6].
Kontinuierliches HMM
Zur Zeit verwendet man zur akustisch-phonetischen
Modellierung bzw. Lautmodellierung meistens das
HMM, besonders das kontinuierliche HMM [8, 9, 10].
In dieser Arbeit wird jeder Laut (SAM-PA) mit dem
5-Zustands-Links-Rechts-HMM modelliert.
Zusätzlich werden Modelle für Pausen und
Rauschen trainiert.
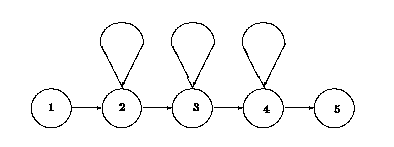
Bild. 1 : HMM für ein Laut-Modell
Für das Training bzw. die
HMM-Parameter-Berechnung
wird
die Baum-Welch-Reestimation
verwendet [7].
Viterbi-Algorithmus
Der Viterbi-Algorithmus wird zur Segmentierung
(Bestimmung der Anfangs- und Endpunkte) der Laute,
aus denen die vorgegebene Transkription des
entsprechenden zu segmentierenden Sprachsignals besteht,
verwendet.
Das Verfahren basiert auf dem Maximum-Likelihood-Kriterium
[7, 10].
Fehlerbewertung
Da es keine objektiven Kriterien zur Beurteilung
der Richtigkeit und Genauigkeit einer automatischen
Segmentierung gibt, wird
die Genauigkeit der Segmentierung der Laute im Vergleich zur Referenz auf
die folgende Weise berechnet und dargestellt: Von der Referenz
(Hand-Segmentierung) abweichende Werte werden zunächst in
segment-eindringende
und segment-überschreitende Fehler unterschieden, um die
Gerichtetheit der
Fehler erkennen zu können. Wegen der unterschiedlichen
Länge individueller
Segmente werden dann die Abweichungen - nach linkem
und rechten Segmentrand
getrennt - berechnet, indem der durchschnittliche auf die Gesamtdauer des
Lautes bezogene Anteil, um den die Segmentierung nach innen in den Laut hinein-
oder über die Lautgrenzen hinausgeht, ermittelt wird.
3. Lauterkennung
Die Lauterkennung wird mit dem HTK-Tool durchgeführt, das
auf den Viterbi-Algorithmus basiert. Das Ergebnis ist eine
Laut-Labeldatei, die zur Bewertung der Erkennungsrate
mit der Referenz-Labeldatei verglichen wird.
Die Erkennungsrate (ER) wird wie folgt berechnet:
ER = (N - D - S - I) * 100 / N
N = Gesamtzahl der Label in Referenzdatei, D = Auslassungen
(deletions),
S = Ersetzungen (substitutions),
I = Einfügungen (insertions).
4. Untersuchungen
Für das Training wurde die CD-1 (Phondat I) benutzt.
Die Sprachdateien wurden zunächst durch Decimation
auf 8 kHz reduziert
und die Bandbreite durch Bandpaß-Filterung
auf den Bereich von 300-3400 Hz begrenzt. Danach wurden
Cepstral-Koeffizienten rahmenweise durch
die Lin-Log-RASTA-PLP-Analyse berechnet. Die
Rahmenbreite beträgt 32 ms und die Rahmenverschiebung
8 ms. Es wurden 12 Koeffizienten pro Rahmen
erzeugt.
Es wurde eine Normtranskription
für jede zu segmentierende Sprachdatei
erzeugt. Diese Transkription und ihre zugehörige
parametrische Sprachdatei wurden als Eingang bzw.
Information für die automatische Segmentierung benutzt.
Dabei wurden 50 Sätze des TUBTEL-Sprachmaterials ausgewählt.
Zum Testen (der
kontext-unabhängigen Lauterkennung) wurden 50
Sätze des TUBTEL-Sprachmaterials
und 50 Sätze
der CD-2 (Phondat I) nach einem Zufallsprozeß benutzt.
Die Bearbeitung des Phondat-Sprachmaterials
(Decimation und Bandbegrenzung) erfolgte wie vorher.
5. Ergebnisse
Automatische Segmentierung
Bild 2 zeigt die durchschnittlichen relativen Abweichungen der
automatischen Segmentierung des TUBTEL-Sprachmaterials
im Vergleich zur Referenz (Segmentierung per Hand).
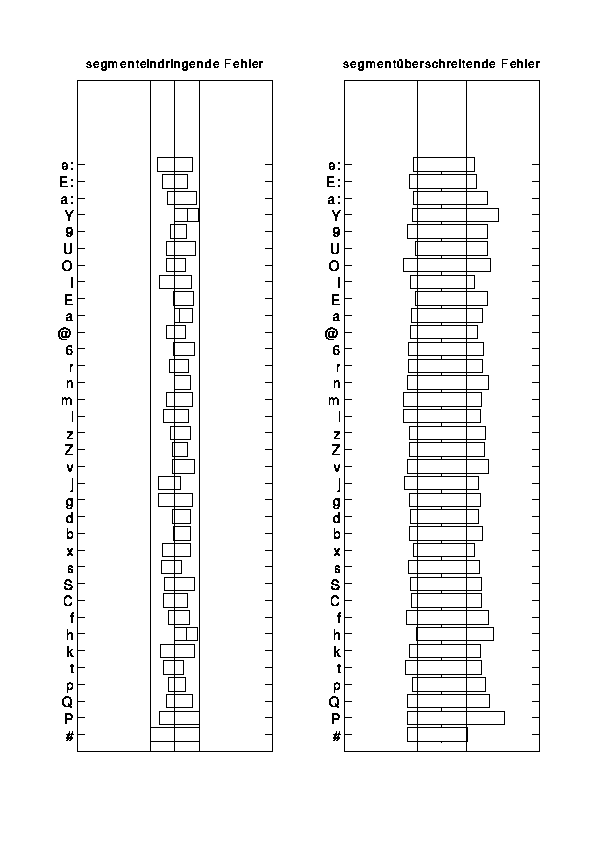
Bild 2 : Gemittelte Abweichungen der automatischen
Segmentierung des TUBTEL-Sprachmaterials
links: segment-eindringende Fehler,
rechts : segment-überschreitende Fehler.
Segmentierungsfehler werden in segment-eindringende (linkes Diagramm) und
segment-überschreitende (rechtes Diagramm) und getrennt nach linker
und rechter Segmentgrenze unterschieden. Die Grafik zeigt - nach Fehlerart
und Laut getrennt - die
durchschnittliche Segmentlänge der gelabelten Laute bei gegebener
Fehlerart. Die vertikalen Linien stellen die korrekten
Lautgrenzen dar.
Die Lautwerte
sind in SAMPA notiert, [P] steht für [Pause], [#] für
das Ende des Signals. Die Ergebnisse sind nach
Lautklassen sortiert. Es zeigen sich keine
lautklassenspezifischen Regelmäßigkeiten. Die Segmentgrenzenerkennung
ist derzeit noch unzureichend.
Mögliche Fehlerquellen sind der Unterschied zwischen der
erwarteten Standard-Lautung und der tatsächlichen Aussprache
(Verschleifungen etc.) sowie unterschiedliche Kanalqualitäten.
Diese Fehlerquellen wurden
bisher noch nicht systematisch untersucht.
Lauterkennung
Die Ergebnisse der Lauterkennung sind in
folgender Tabelle zusammenfaßt. In der zweite Spalte ist
die Erkennungsrate für das gefilterte Phondat-Sprachmaterial,
das aus den 50 Sätzen der Phondat I (CD-2) besteht.
Damit hat das
Testmaterial die gleiche Qualität wie das Trainingsmaterial.
In der dritten Spalte ist die Erkennungsrate für das
TUBTEL-Sprachmaterial. Die Qualität des zweiten Testmaterials
ist schlechter als die des ersten.
| Testdaten
Phondat I CD-2
(gefiltert) | Testdaten
TUBTEL |
|---|
| Trainingsdaten | 48 | 27 |
|---|
Die Erkennungsrate bei Telefonsprache ist schlecht
in Vergleich zur derjenigen der gefilterten Phondat-Sprachdatenbank.
Mögliche Fehlerquellen sind die unterschiedlichen
Textsorten und die jeweilige Sprachqualität.
6. Zusammenfassung und Ausblick
Es zeigt sich, daß die automatische Verarbeitung von Telefonsprache
unter Zuhilfenahme von Studio-Qualitäts-Daten bisher noch suboptimale
Ergebnisse erzielt. Die Untersuchungen geben aber Anhaltspunkte für
weitere Arbeiten zur Lauterkennung deutscher Sprache unter
Telefonbedingungen. Ansatzpunkt zur Verbesserung der Ergebnisse
ist u.a. eine stärkere Anpassung der Trainingsbedingungen
an die Testsituation.
Daher ist es notwendig, den Einfluß der Sprachqualität auf
die Erkennungsrate systematisch durch eine Kanalsimulation
zu untersuchen.
In diesen Untersuchungen war bisher der Faktor J für die
Lin-Log-RASTA-Filterung noch konstant. Dieser
Faktor soll noch an das SNR des zu untersuchenden Signals angepaßt
werden.
Literatur
[1] Unterlagen der Phondat-CDs.
[2] Schürer, T., Ahrling, S., Fellbaum, K., Hardt, D.,
Klaus, H., Mengel, A., Suhardi; TUBTEL - Eine deutsche
Telefon-Sprachdatenbank; Elektronische Sprachsignalverarbeitung;
Wolfenbüttel, 4.-6. September 1995, ISSN: 0940-6832,
pp. 183-187.
[3] Weintraub, M., Neumeyer, L.; Constructing Telephone
Acoustic Models from a High-Quality Speech Corpus; ICASSP-94,
pp. I-85-I-88.
[4] Neumeyer, L. G., Digalakis, V. V., Weintraub, M.;
Training Issues and Channel Equalization Techniques for the
Construction of Telephone Acoustic Models Using a High-Quality
Speech Corpus; IEEE Trans. on Speech and Audio Processing,
Vol. 2, No. 4, October 1994, pp. 590-597.
[5] Moreno, P. J., Stern, R. M., Sources of Degradation of
Speech Recognition in the Telephone Network; ICASSP-94,
pp. I-109-112.
[6] Hermansky, H., Morgan, N.; RASTA Processing of Speech;
IEEE Transactions on Speech and Audio Processing, Vol. 2,
No. 4, October 1994, pp. 578-589.
[7] Young, S.J., Woodland P.C., Byrne, W.J., HTK:
Hidden Markov Model Toolkit User Manual, 1993,
CUED Speech Group Cambridge University, Entropic Research
Laboratories Inc.
[8] Lee, C.H., Rabiner, L.R., Pieraccini, and Wilpon, J.G.;
Acoustic Modeling for Large Vocabulary Speech Recognition.
Computer Speech and Language, 4: 1237-1265, January 1990.
[9] Lee, K-F., Hon, H-W.; Speaker Independent Phone
Recognition using
Hidden Markov Models. IEEE Trans. on ASSP, pp. 1641-1648.
[10] Huang, X. D., Ariki, Y., Jack, M.A.; Hidden Markov
Models for Speech Recognition, 1990, Edinburgh
University Press.